Table of contents
The fastest way to answer a business question used to be expensive: an analyst on staff, a clean warehouse, a dashboard for every recurring ask. Then AI tools made the fast answer free for everyone. The analytics line item, oddly, did not shrink. Speed became free. Defensibility became the line item.
TL;DR
- Getting an answer out of your data used to cost analyst hours, data engineering, and tooling overhead. AI collapsed that cost to roughly nothing for any team that wants to ask.
- The budget that used to buy speed did not disappear. It moved into three places: verification work, the cost of acting on numbers that turn out to be wrong, and the infrastructure that prevents both.
- The line item now is cost-per-trusted-answer, the spend it takes to be able to stand behind a number in a meeting without rebuilding it from scratch.
- The cheapest source of defensibility is infrastructure at the data layer: governed metric definitions, computation that runs in tested code rather than in a language model, and a system honest enough to say when it does not know.
- A marketing leader planning next year’s spend should track how much it costs to defend a number, not how fast the team can get one.
Introduction
Every AI tool on the market now answers an analytics question in seconds. The marginal cost of a fast answer is approximately zero. So why is the analytics budget the same line item it was two years ago?
The answer is awkward. Speed was never the only thing the analytics spend was buying. Cleaner pipelines, a dedicated analyst, a dashboard for every recurring question: those bought speed, yes, and they also bought defensibility, the ability to walk into a board meeting with a number the team could stand behind. Pull the speed component out and price it at zero, and the defensibility component stays exactly where it was. The remaining cost becomes visible in a way it was not before.
The thing the budget paid for, quietly, got repriced.
What the analytics line item actually used to buy
Two years ago, the bottleneck was access. A marketing leader who wanted to know why demo-to-close slipped last quarter waited a day or two on the data team, or rebuilt the answer in a spreadsheet, or accepted a delay until the next reporting cadence. The cost of an answer got measured in elapsed time and analyst attention. Teams paid that cost in headcount, warehouse fees, dashboard tooling, and reporting cycles.
In Databox’s Time to Insight survey, 64% of teams said it takes one to three days to gather the data needed to answer a single business question.
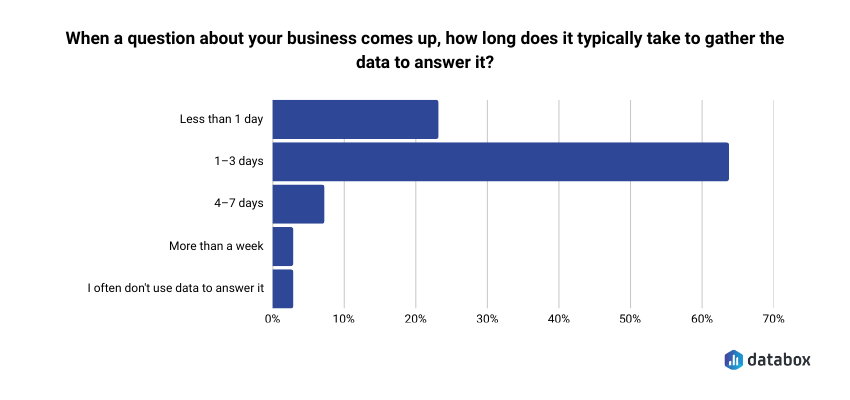
The slow path is still real, and the budget is still being spent on it.
So far, so familiar. What changed is what sits next to it.
Speed got commoditized. The budget got re-spent in three places.
AI made the fast answer universal. In Databox’s AI Adoption in SMBs research, 89% of companies reported already using AI in their operations, and 87% were using generative AI.
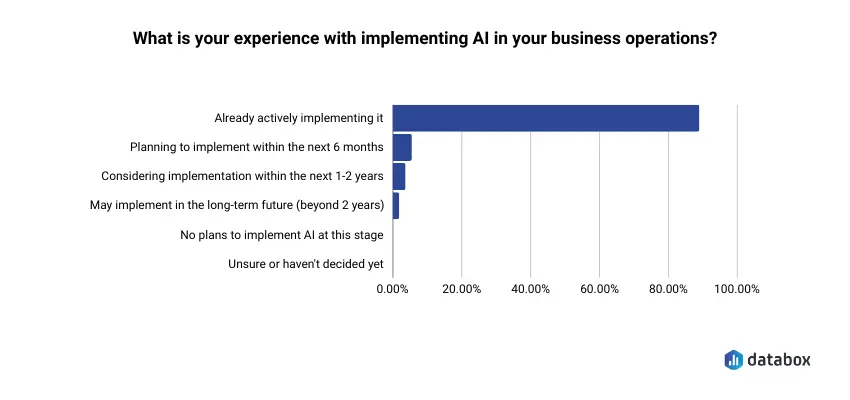
Any marketing leader can now skip the three-day wait, connect a data source to an AI tool, ask a question in plain language, and read a fluent answer in seconds. The latency that a team used to pay an analyst to reduce is gone.
The cost did not vanish with it. It moved.
It went to verification work first. Before a number gets pasted into a board deck, someone has to confirm it: open the dashboard, run the query, ask the analyst to spot-check. Most teams know the work happens; few of them price it. In Databox’s Managing Your CRM and Customer Data survey, 60% of teams said they occasionally find discrepancies in their customer data, and the most common confidence level teams reported in that data’s accuracy was “somewhat confident.”
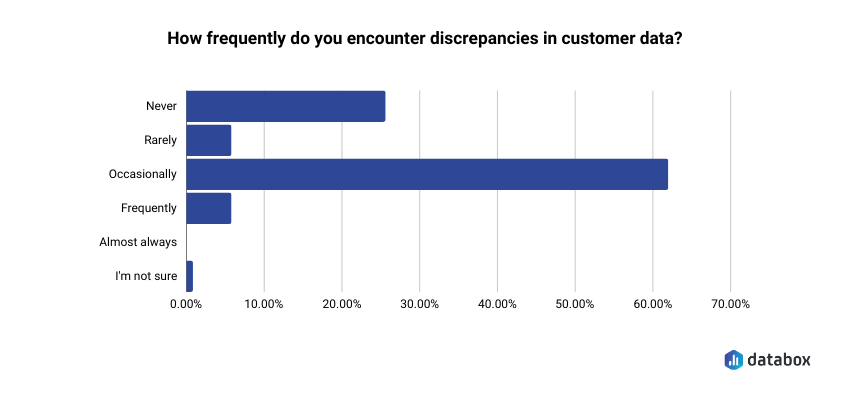
Verification is a tax on every AI-assisted answer; the team that skips it pays the next cost instead.
The next cost is risk absorption. When a confident wrong number goes into a decision unchecked, the team eats the consequences: reallocated spend against a figure that was never real, a forecast they have to walk back, a campaign extended on the wrong premise. The line item for that does not appear in the analytics budget. It shows up later, in the marketing budget.
And the third place the budget can go is infrastructure that makes the other two unnecessary at the source. Governed metric definitions, computation that runs in tested code instead of in a language model, and a system honest enough to say when it does not know. The spend looks different from buying analyst hours, but the function is the same: it lets the team stand behind a number without rebuilding it.
The total cost of getting and acting on an answer stayed roughly where it was. The mix changed, quietly, and most analytics budgets have not been re-drawn around it.
The line item now is cost-per-trusted-answer
The number worth tracking has changed. “How fast can the team get the answer” was the right question when speed was the bottleneck. Speed is the bottleneck for nobody now. The right question is how much it costs the team to defend the answer they got: minutes to verify, dollars at risk if they do not, hours of analyst time pulled into spot-checking.
Cost-per-trusted-answer is a useful frame because it makes the hidden line items visible. A team that gets an AI answer in eight seconds and spends forty minutes verifying it has not actually moved faster than the team that takes a day to produce a number nobody questions. A team that gets an AI answer in eight seconds, skips the verification, and walks back one decision a quarter because of it pays the bill in a different P&L row, and probably at a worse exchange rate.
Reframing this way changes what the analytics budget is buying. Tools that lower the per-answer verification cost, the kind that hand back a number a marketing leader can sign off on in seconds rather than minutes, look obvious in a way they did not when speed was the headline. Tools that compress time-to-answer without addressing defensibility look cheap on price and expensive on operation.
In Databox’s Time to Insight survey, 48% of teams named a single standardized definition for core metrics as the change that would most improve the trustworthiness of their reporting, the most-chosen answer ahead of more access, more tooling, or faster refreshes.
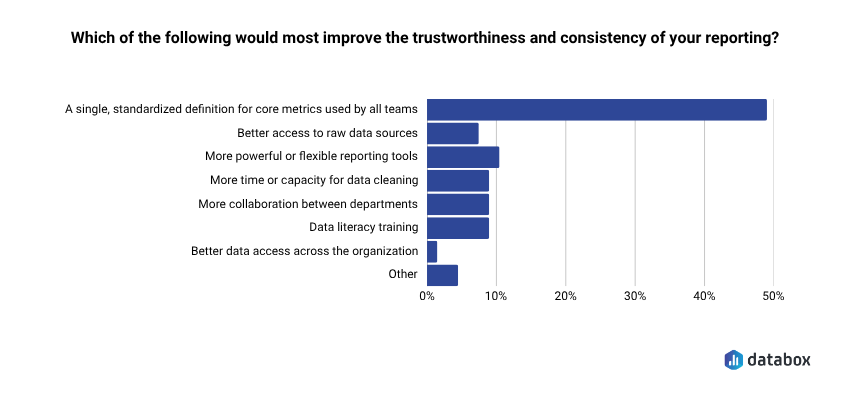
The teams already buying defensibility know what they want: definitions everyone agrees on. Definitions are infrastructure, not features, and infrastructure is what the analytics budget can buy now that speed is off the menu.
What lowers cost-per-trusted-answer
Three pieces of infrastructure each cut one of the costs above. They are not magic; they are the components of a line item with a different name on it.
Governed metric definitions cut verification cost. When the question and the dashboard use the same definition of ‘pipeline’ or ‘qualified lead,’ verification stops being a manual step. A marketing leader asks, sees the result, and does not need to mentally re-check whether the system meant the same thing they did.
Deterministic computation cuts risk-absorption cost. A language model approximating arithmetic by predicting the most likely next word is fast, fluent, and wrong some percentage of the time. The same question routed through code that runs the calculation produces a number the team can show its work on. In Raymond Panko’s spreadsheet accuracy research, cell error rates ran roughly one to five percent across studies, the historical baseline for the cost of manual arithmetic and the floor any tool replacing manual work needs to beat.
Abstention cuts the cost of acting on a fabricated number. A tool that says “I do not have the data to answer this” when the data is missing does not look impressive in a demo, and it saves a meaningful number of bad decisions a year.
Databox built Genie, the AI analyst inside Databox, around the three. When a VP of Marketing asks Genie why cost per lead rose in paid social last week, the calculation runs in deterministic code against the connected data, Genie reads the metric definitions the team already locked into the workspace, and if the data is not there, Genie says so. The marketing leader skips the verification tax, absorbs no risk from a fabricated number, and gets a number that reconciles to what the Databoard would show.
"Talking to Genie and creating reports/dashboards (in seconds) is truly mind-blowing. As someone who is constantly exporting data, uploading it to various places, and writing formulas to connect it all, it almost felt too good to be true. In just a few clicks, I had my most-used tools integrated and data pulled up. I wish I had found this sooner."
For teams that prefer to keep asking from inside the AI tool they already use, Databox MCP extends the same infrastructure to Claude, ChatGPT, and similar tools. The interface stays the same; the cost structure underneath changes.
The analytics line item did not move because the thing it was buying did not become free. What became free was the easy half. A marketing leader who can show the CFO where the budget goes now, line by line, planned for the shift. A marketing leader who cannot is paying the new cost anyway, in verification cycles, walked-back decisions, and the slow drift of trust the team used to take for granted.
The next analytics tool worth paying for is the one that lowers cost-per-trusted-answer. Defensibility is the line item now.
For the deeper version of how grounding works underneath an AI answer, see the Databox piece on why AI agents need a semantic layer. For the related question of whether an AI answer is structurally trustworthy, see Your AI Tool Gives Confident Answers. Are They Based on Your Actual Data?
Frequently Asked Questions
Why did AI tools make fast answers free?
Large language models read a question in plain English, infer what data it refers to, and produce a fluent paragraph in seconds. The marginal cost of doing that is the cost of a few API calls, and most analytics products bundle it into existing pricing. Any team with a data source and an AI tool can now ask “which channel drove pipeline last month” and read an answer before the next meeting starts. The work an analyst used to do in elapsed hours happens in seconds, at near-zero variable cost.
If speed is free, why are analytics budgets not shrinking?
Because speed was not the only thing the budget was buying. Analyst hours, data engineering, and dashboard tooling also bought defensibility, the ability to stand behind a number in a meeting. When the speed component became free, the defensibility component stayed at the same cost. It became more visible. Most teams are still paying for it, often without naming the line item.
What is cost-per-trusted-answer and how do I measure it?
Cost-per-trusted-answer is the total spend it takes to get to an answer the team can act on, including the AI cost, verification time, and the expected cost of being wrong when an answer is not verified. A marketing leader can measure it by tracking how many minutes the team spends checking an AI-generated number before using it, plus the cost of decisions reversed because an unverified number turned out to be off. The number is rarely zero, and most teams underestimate it.
What is the difference between an AI answer that is verified and one that is grounded?
A verified answer is one the team checked manually after the fact, usually by opening the dashboard and confirming the number. A grounded answer did not need to be checked because it used the agreed metric definitions and ran the calculation in tested code from the beginning. Verification is a cost the team pays per answer. Grounding is infrastructure the team pays for once, and the per-answer cost drops to near zero.
How is Databox Genie different from giving an LLM access to my data?
A general-purpose LLM with access to your data still does the arithmetic itself, by predicting likely text, and still infers what terms like “pipeline” mean from context. Genie separates the work: the language model handles the question and the explanation, the calculation runs in deterministic code against your connected data, and the definitions come from the metrics your team already locked into the workspace. If the data needed is not available, Genie says so rather than guess. Databox MCP extends the same separation to Claude or ChatGPT, so an answer asked from those tools reconciles to your dashboard.