



")
Table of contents
TL;DR
- The agent isn’t the problem. The context it reads from is. Pointing a capable LLM at a warehouse without governed business context will give you fluent answers that are subtly or significantly wrong, stated with full confidence.
- A semantic layer for AI has two context layers most writing about this conflates: a semantic model (what the data means — entities, relationships, descriptions, synonyms) and metric definitions (how a business number is actually calculated). They do different jobs and you need both.
- Governance is a third layer on top of semantics. Without ownership, verification, lineage, and access rules attached to each metric, an agent can pull a perfectly real definition of “revenue” and still pick the wrong one — because nothing told it which definition the business stands behind.
- The moat is whether your semantic layer can be read by every surface — dashboards, agents, APIs, CLIs — or whether it’s locked inside one BI tool. As LLM capability commoditizes, the differentiator is the governed context underneath.
Everyone is racing to put an AI agent on top of their data. Almost nobody is asking whether the agent can be trusted to act on what it sees.
That is the wrong order. And the way most teams are trying to fix it — bigger context windows, more reasoning, another eval — is also wrong.
The generative model stopped being the hard part of agentic analytics months ago. Wiring an LLM to a warehouse is a weekend project. The hard part is everything underneath: what a metric means, who owns it, how it’s calculated, how the entities relate, and whether the number the agent returned is one a human would defend in a board meeting.
That underneath is the semantic layer. And it’s quietly becoming the most important piece of infrastructure in your data stack.
The agent isn’t the bottleneck. The context is.
The familiar failure pattern goes like this. A team connects a capable AI model to their data warehouse. They ask it a business question. It returns a fluent, confident answer. The answer is wrong — sometimes obviously, more often subtly. The team’s first instinct is to reach for a better generative model: more parameters, bigger context window, another round of prompt engineering.
That instinct is wrong because it misdiagnoses the problem. The agent isn’t failing at reasoning. It’s failing at business comprehension. It doesn’t know what “active customer” means in your company. It doesn’t know whether your revenue figure excludes refunds. It can see thirty tables that look like they might contain “lead time” and has no way to pick the right one. So it guesses, fluently.
This is the gap a semantic layer fills. Not a better model. A better layer of context between the raw data and whatever’s reading it — human analyst, dashboard, AI agent. The model becomes a generic capability that any vendor can offer. The semantic layer becomes the thing that determines whether the answer is right.
Two kinds of context AI agents actually need
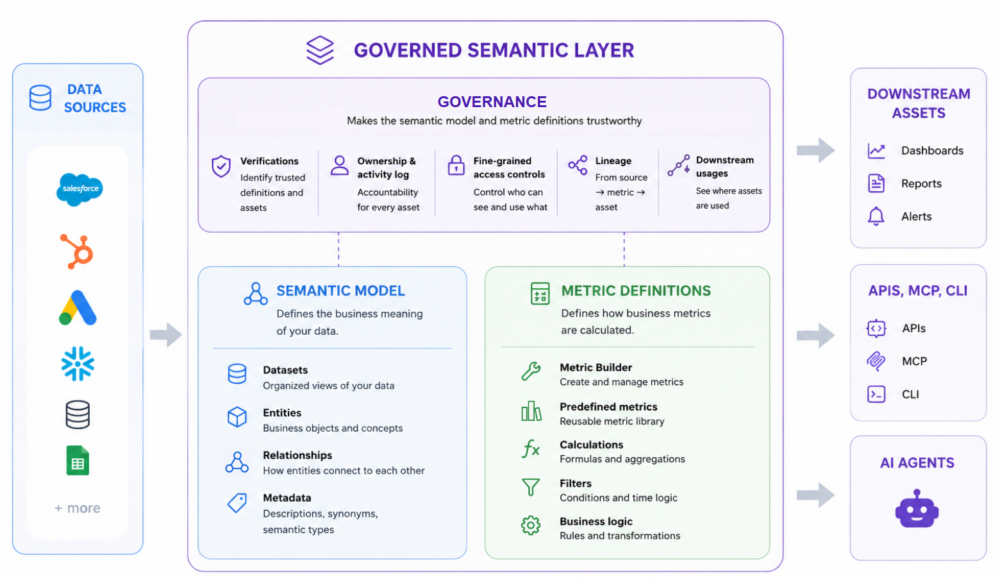
Most writing about semantic layers for AI lumps everything into one bucket: “definitions and metadata.” That framing hides the most important distinction. A semantic layer for AI actually has two context layers that do different jobs, and you need both.
The first is the semantic model. This is a structured description of your data in business terms. Not the raw tables — the meaning laid over them. It includes entities and how they relate, measures and dimensions, descriptions, synonyms, and semantic types that flag whether a field represents a country, a URL, or a marketing channel. The semantic model is what tells an agent what a column actually means and which table to use. Ask about lead time, and this is what connects the phrase to days_to_delivery instead of a guess.
The second is metric definitions, built on top of the semantic model. This is the exact way the business wants a specific number calculated. What counts as revenue. Whether canceled orders are excluded. Whether it’s a sum, a count, an average, or the latest snapshot. What grain it’s measured at. Which filters are always part of it.
Here’s why the distinction matters. Suppose an agent sees a column called order_amount. The semantic model can tell it that this column represents the monetary value of an order at the moment of purchase. Useful. But ask the agent to “show me revenue last quarter,” and the semantic model alone can’t help. Does revenue mean gross or net? Does it include canceled orders? Does it include returns? Is it booked or recognized? Is it net of refunds, or are refunds reported separately?
Only the metric definition can answer that. And the answer is specific to your business, not deducible from the column name. The semantic model points the agent at the right ingredients. The metric definition tells it which recipe to use.
This is where most teams fail. They invest in a semantic model — usually because their BI tool requires one — and assume that’s enough to make AI accurate. It isn’t. An agent with a great semantic model and no metric definitions will still pick the wrong version of revenue, confidently. An agent with both will compute the answer the same way your finance team would.
Why definitions aren’t enough — governance is a third layer
Even if you have both layers, you’re not done. Most companies have several versions of “revenue” floating around: one for the finance team, one that marketing built for attribution reporting, one that someone in growth experimented with last quarter and never deleted, one that the data team marked as canonical six months ago and may or may not still be.
An agent can pull any of these. They’re all real metric definitions. Nothing in the definition itself tells the agent which one the business actually stands behind.
This is where the third layer — governance — earns its keep. A governed semantic layer carries signals beyond the definition itself:
- Ownership shows who is accountable for the metric. If something looks wrong, there’s a person to ask.
- Verification shows which version the business has endorsed. The marketing team’s experimental revenue definition isn’t verified. The finance-owned one is.
- A review date keeps anyone from trusting a definition that quietly went stale six quarters ago.
- Access rules keep sensitive numbers — payroll, customer-level revenue — restricted to people cleared to see them, and apply the same restriction to agents acting on a user’s behalf.
- Change history lets you trace why a number moved. If revenue dropped 4% week-over-week, was that the business, or was that a definition change?
- Lineage ties the metric back to the source data, so any answer can be audited end to end.
When these signals are absent, an agent’s confidence is unearned. When they’re present and machine-readable, an agent doesn’t just have a definition. It has a choice criterion: prefer the verified, currently-owned, recently-reviewed metric over the experimental one. The same logic a careful analyst would apply.
This is the difference between an agent that answers fluently and an agent the business will actually let act on what it sees.
Why no one will hand-author a semantic layer (and why that’s fine)
Anyone who’s read this far is having a fair objection: this all sounds like a tremendous amount of manual work. Documenting entities. Writing metric definitions for every KPI. Marking ownership. Verifying. Reviewing. Maintaining.
It would be, if humans had to do it from scratch. They don’t, and they won’t.
The teams that ship working semantic layers for AI aren’t authoring everything by hand. They’re populating most of the layer automatically and reviewing the parts that need human judgment. There are roughly four ways this happens in practice.
Connection-time pre-fill. When you connect a source, basic semantic metadata arrives with it. Key entities are described. Common synonyms are mapped. The relationships between entities are inferred from foreign keys and naming patterns. Much of the semantic model exists before anyone touches it.
Predefined metrics for managed sources. For platforms a vendor knows intimately — Stripe, Shopify, HubSpot, the major ad platforms — the metric definitions can ship with the integration. Stripe MRR is the same calculation in every company that uses Stripe. Shopify Revenue is computed the same way. For these sources, the definitions don’t need authoring; they need vendor-grade defaults that you can override if your business measures differently.
Inferred context from the surroundings. For metrics the vendor doesn’t know about, an AI agent can infer meaning from the context already present: column names, sample values, existing queries, dashboards built on top of the column, how it’s used in goals. The signal is usually already there, just not collected in one place.
AI-suggested metadata on demand. When something genuinely needs to be filled in, the user isn’t starting from a blank field. The agent suggests a description, a synonym, an aggregation — drawn from the context it has gathered — and the user reviews and accepts. Authoring becomes editing.
The shape of the work changes. Users are no longer documenting the semantic layer from a blank page. They’re reviewing, correcting, and verifying semantics that are already mostly in place. That’s the difference between a semantic layer teams actually maintain and one they abandon after a quarter.
The semantic layer becomes infrastructure when it’s readable by everything
A semantic layer that only your BI tool can read is doing half its job.
The definitions, relationships, and trust signals you build are most valuable when they can be read from anywhere. The same metric definition should power a Monday-morning dashboard, a scheduled board report, a natural-language question asked in chat, an API call from an external app, and a query an autonomous agent writes on its own. One definition. Many surfaces.
This is the part that matters most for agentic analytics. When an agent answers a question about revenue, it shouldn’t invent its own version of revenue. It should read the exact definition your finance team verified, through the same layer a human analyst would. One source of truth, whether the thing asking is a person or a model.
The shift here is significant. A semantic layer locked inside a BI tool is a feature of that tool. A semantic layer that any client can read — through standards like the Model Context Protocol (MCP), or through APIs, or through a CLI — is infrastructure. Other tools build on top of it. Agents build on top of it. Your own product can build on top of it. The semantic layer stops being something users log into and starts being something other systems depend on.
This is the architectural direction the market is moving. The semantic layer is becoming the standard interface between an organization’s data and any agent that wants to act on it. Databox’s MCP server is one of the surfaces designed around this shift; the broader pattern matters more than any single implementation.
The moat is the metadata
As LLM capability becomes a commodity — and that commoditization is now visibly underway — the differentiator in AI-powered analytics shifts from the model to the layer beneath it. Two companies can run the same model against the same warehouse and get completely different quality of answers, depending on what their semantic layer looks like.
The companies that treat the semantic layer as infrastructure now — author once, govern centrally, open to every surface — will have agents whose answers are defensible in front of a CFO. The companies that don’t will have agents that guess fluently. The first group will deploy autonomous workflows with confidence. The second will keep finding reasons not to.
The race that matters in agentic analytics isn’t who ships an AI agent first. It’s who ships the layer underneath that makes the agent worth trusting.a single question. It is the one that produces answers you can use to reallocate spend before a quarter closes, share in a pipeline review, or defend in a budget meeting. At the beginning of this article, Claude gave you an MRR number. Confident, well-formatted, completely wrong. Databox MCP is how you make sure the next answer is the real one.
See what an agent looks like reading from a governed semantic layer
The architectural shift in this piece is already running in production for teams who’ve moved past the “point an LLM at the warehouse and hope” pattern. To see what agentic analytics looks like when the semantic layer underneath is built right, read the piece on agentic analytics in practice — the workflows, the time recovered, and what changes when the loop closes.
Frequently Asked Questions
What is a semantic layer for AI?
A semantic layer for AI is a structured, machine-readable description of your business data — the entities and how they relate, the metrics and how they’re calculated, and the trust signals that tell an AI agent which definitions to use. It sits between raw data and any system reading it (human analyst, dashboard, AI agent), and it’s what allows an agent to answer business questions consistently and correctly.
How is a semantic layer different from a data catalog?
A data catalog documents what data exists, where it lives, and who owns it. A semantic layer goes further: it encodes how the data is calculated into business metrics, how entities relate, and which definitions are authoritative. Catalogs are largely passive — they describe. Semantic layers are active — they’re queried at runtime to produce consistent answers across dashboards, APIs, and AI agents.
Do I need a semantic layer if my AI tool already connects to my data warehouse?
Connection is not comprehension. An AI tool with warehouse access can read your tables, but it can’t know what “active customer” means in your business, or which of three competing revenue definitions to use. Without a semantic layer, the agent has to infer business logic from column names — and inference at the point of action is where hallucinations and silently-wrong answers happen./
What’s the difference between a semantic model and metric definitions?
The semantic model describes what the data means: entities, relationships, descriptions, synonyms, the meaning of each column. Metric definitions describe how a specific business number is calculated: the formula, filters, grain, and aggregation. A semantic model can tell an agent that a column represents order value. Only a metric definition can tell the agent whether “revenue” means gross, net, recognized, or net-of-refunds. You need both.
Can an AI agent use a semantic layer through MCP?
Yes. MCP (Model Context Protocol) is becoming the standard interface through which AI agents read business context from external systems. A semantic layer exposed via MCP lets any compliant agent — Claude, ChatGPT, an in-house agent built on any frontier model — query governed metric definitions instead of guessing at SQL against raw tables. The same layer that powers your dashboards can power your agents.
Does a semantic layer for AI replace dbt, Looker, or my BI tool?
No. These tools play different roles. dbt is excellent for code-first metric definitions managed by data engineers. BI tools like Looker and Power BI model and organize reporting inside their own surfaces. The category of semantic layer for AI is narrower: a governed, metric-centric layer that’s designed from the start to be read by AI agents and humans through the same interface, not bound to one BI tool’s walls.






