




Table of contents
A five-question audit, with the exact prompts to paste, walked through on a real LinkedIn CPL spike.
TL;DR
- The most expensive mistake marketing managers make with ChatGPT, Claude, and Gemini in 2026 is treating a confidently context-invented answer as analysis, because the failure mode doesn’t trip the usual hallucination checks.
- Generic LLMs substitute training-data assumptions for missing business context, and present the substitution as fact. The substitution is not flagged because it isn’t, technically, an error — it’s a guess the model has to make to answer the question at all.
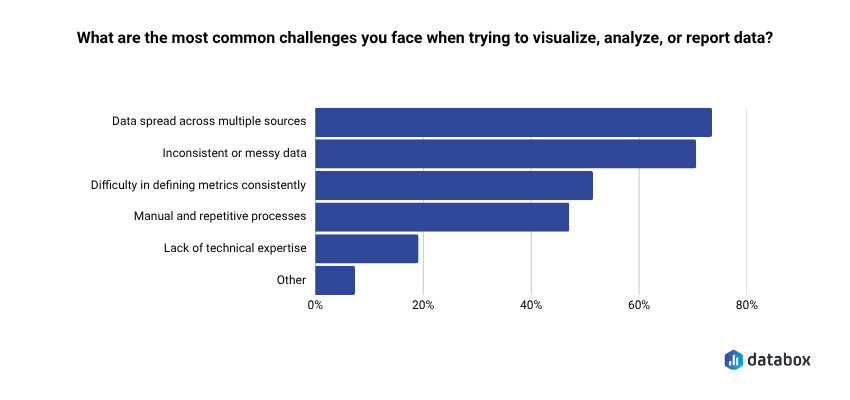
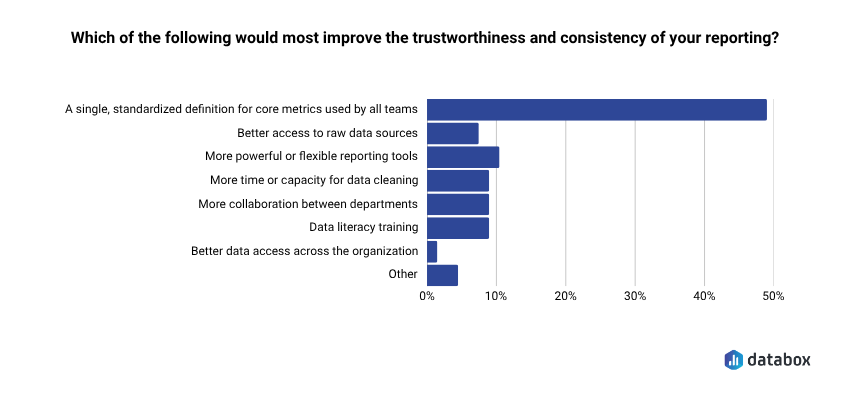
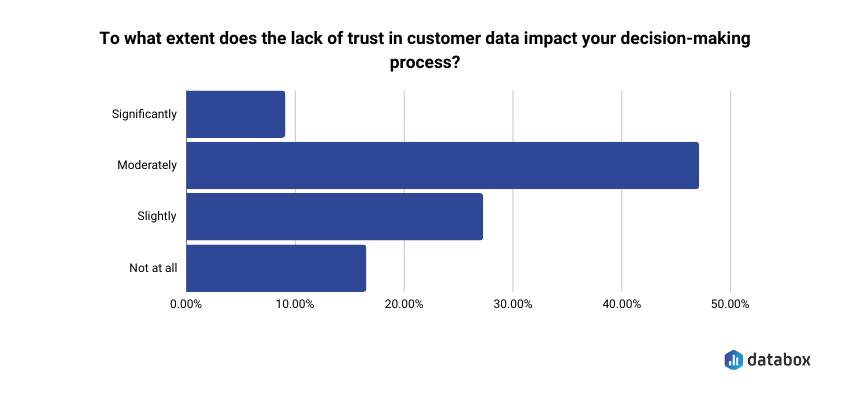
- 73.13% of marketing and analytics teams identify data spread across multiple sources as their top reporting challenge, and 48.48% say a single standardized definition for core metrics would most improve trustworthiness — the exact gap LLMs fill with training-data assumptions (Databox Time to Insight research).
- The five-question audit takes about ten minutes and uses five copy-paste prompts you can save as snippets. Context-aware AI tools that read your actual data and metric definitions resolve most of the structural problem before the audit has to do any work.
Introduction
It is Wednesday morning. A marketing manager at a B2B SaaS company opens her LinkedIn Ads dashboard and sees the number she was afraid of. LinkedIn CPL has spiked 60% week over week. Her board update is Friday. The Head of Demand Gen wants a diagnosis and a plan by tomorrow’s stand-up.
She pulls the last eight weeks of LinkedIn campaign performance into a CSV. She’s been using ChatGPT for marketing analysis since 2024. She knows the obvious failure modes like invented vendors, made-up case studies, confidently wrong dates, and she spot-checks for them automatically. None of that habit prepares her for what comes back.
She pastes the data and asks: “Why did my LinkedIn CPL spike this week, and what should I do about it?”
ChatGPT returns a confident answer in about twelve seconds. Audience saturation is likely. Creative fatigue is a probable contributor. Industry CPL benchmarks for B2B LinkedIn campaigns are typically $50 to $200, and her current $113.79 is in the middle of normal. Recommendations: rotate three new creative variants, tighten audience targeting on the top-performing segment, and review bid caps against the benchmark range.
She reads it twice. The recommendation is specific. The numbers all look real. Nothing pings her hallucination radar. But something is off, and she can’t immediately name what.
What is off is this: she does not remember telling ChatGPT what industry she’s in, what her sales cycle looks like, what her actual CPA target is, or how her ICP-built custom audience compares to “standard” B2B LinkedIn targeting. The answer is treating those as resolved when she never resolved them.
Every confident wrong answer from a generic LLM is a correct answer to the question the LLM thought you asked. Spot-checking the answer for hallucinated facts is the wrong check at the wrong layer. The verification she needs is one step upstream: did the LLM understand her question and her business in the first place? Validation of the answer comes after that work, not before.
The guide below is the five-question audit that catches the gap. Each question has a copy-paste prompt. We will run all five against the same LinkedIn CPL conversation and watch ChatGPT’s answer change as we go.
Generic LLMs Were Not Built for Your Marketing Data
ChatGPT, Claude, Gemini, and Copilot are trained on internet-scale text. The training objective rewards fluency. The training data is everyone else’s marketing content, never the marketing manager’s specific business.
Three structural behaviors look like analysis but are mechanically different from analysis.
Context invention. The LLM has no information about industry, sales cycle, average deal size, audience definitions, conversion benchmark history, or what counts as a conversion event in this business. When that context is missing, the LLM fills the gap with patterns learned during training. Patterns learned from B2C e-commerce data get applied to B2B SaaS questions. The LLM does not flag the substitution. It presents the inferred context as if it were the marketing manager’s actual context.
Fluency over accuracy. The LLM was trained to produce text that reads well, not text that is verifiably correct. A response with hedges, gaps, and “I cannot determine this from the data you provided” sentences scores worse on fluency than a response with clean recommendations and confident percentages. The training pressure runs against acknowledged uncertainty. The model rounds confidence up.
Leading-question accommodation. Ask “why did CPL spike,” and the model finds reasons CPL spiked. Ask “Is my campaign healthy?” and the model finds reasons the campaign is healthy. The same underlying data supports different answers depending on the framing because the model follows the framing rather than interrogating the data.
This isn’t a niche failure mode. The structural conditions that force the LLM to invent context — fragmented data, inconsistent metric definitions, low trust in the underlying numbers — are the dominant working conditions for most marketing teams.
In Databox’s Time to Insight research, 73.13% of marketing and analytics teams identified data spread across multiple sources as their top reporting challenge, and 71.64% cited inconsistent or messy data as a common obstacle. When asked what would most improve trustworthiness of their reporting, 48.48% named a single standardized definition for core metrics.
Generic LLMs operate inside that gap. Every time a metric definition is missing from the prompt, the LLM substitutes the average it learned from training data and presents the substitution as if it came from the marketing manager’s account.
The structural failure rate does not change with model improvements. A more capable LLM with no access to the marketing manager’s actual metric definitions still invents them; it just invents them more fluently. The audit below is the workflow that catches the invention before it reaches a stakeholder. For the full breakdown, read How to Improve Your CRM Data Management Based on Insights From 140+ Companies
The Five-Question Audit, Run on a Real LinkedIn CPL Spike
The audit verifies the LLM’s comprehension, not its output. Each question has a specific prompt to paste. The whole sequence takes about ten minutes the first few times and far less once the prompts are saved as snippets. Run the questions in order on the same conversation you used to ask the original question.
We will use the LinkedIn CPL conversation from the introduction. Same marketing manager, same campaign data, same ChatGPT thread.
Question 1: Did the LLM understand the question I actually asked?
Prompt to paste:
Before you go further, rephrase my original question back to me in your own words. List every ambiguity you had to resolve to interpret it. Wait for my confirmation before continuing.
ChatGPT’s rephrase on the LinkedIn question reveals interpretation drift. The marketing manager asked: “Why did my LinkedIn CPL spike this week, and what should I do about it?” ChatGPT’s rephrase: “You want to understand the most likely causes of CPL increases in B2B LinkedIn advertising and receive recommendations on standard optimization tactics.”
The two questions are different. The marketing manager wants to know what happened this week in her account. ChatGPT interpreted the question as a request for general causes of CPL increases across B2B LinkedIn advertising. The original answer was correct for the second question and irrelevant to the first.
She corrects the prompt: “I want to know what specifically changed this week in the data I gave you. Not general causes.” The correction alone narrows the next answer’s scope by roughly half.
Question 2: Did the LLM understand my business context?
Prompt to paste:
List every assumption you made about my industry, sales cycle, average deal size, customer acquisition cost, audience definition, and conversion rates to produce this analysis. Flag anything you assumed because the information was missing from my prompt.
ChatGPT’s assumption list on the LinkedIn question is long. Industry assumed: B2B SaaS in general. Sales cycle assumed: 30 to 90 days. Average deal size assumed: $5,000 to $25,000 ACV. CPL benchmark range assumed: $50 to $200 (drawn from training data). Audience definition assumed: similar to standard LinkedIn B2B audiences.
The marketing manager’s actual business: B2B SaaS with a 9-month average sales cycle, $80,000 average ACV, custom CPA targets tied to her ICP-specific campaigns, and a custom audience built from her CRM customer data rather than off-the-shelf LinkedIn targeting.
Every one of ChatGPT’s assumptions is wrong. The recommendation to “review bid caps against the benchmark range” was anchored to a $50-to-$200 range that does not apply to this business at all. Acting on that recommendation would have tanked her audience reach for a benchmark that was never hers.
Question 3: Did the LLM use my data, or invent benchmarks from its training?
Prompt to paste:
For every number you used in your analysis, label whether it came from the data I provided in this conversation or from your training data. Identify any number whose source you cannot determine.
ChatGPT’s labeled response on the LinkedIn question is clarifying. The current CPL of $113.79 came from the marketing manager’s input data. The week-over-week spike of 60% came from her data. The “industry benchmark range of $50 to $200” came from training data. The claim that “audience saturation typically appears after 8 to 12 weeks of consistent targeting” came from training data. The recommended creative rotation cycle of 3 to 4 weeks came from training data.
The decision basis collapses. Three of the five anchor numbers in ChatGPT’s original recommendation came from training data, not from the marketing manager’s account. A budget recommendation built on three invented numbers and two real ones is not a budget recommendation. It is a hallucination with a chart.
Question 4: Did the LLM know what it didn’t know?
Prompt to paste:
What three pieces of information, if you had them, would most change your answer to my original question? What conclusions in your current answer are you least confident about, and why?
ChatGPT lists three blind spots. First, it did not have visibility into auction-level changes (competitive bidders entering the marketing manager’s audience, average cost per impression trends day by day). Second, it did not have visibility into audience health (audience size, frequency exposure, click-through rate by segment). Third, it did not have visibility into upstream changes (creative refresh dates, targeting changes, and budget changes that the marketing manager might have made).
Each of those is something the marketing manager has access to inside her LinkedIn account and her CRM. None of them are in the CSV she pasted. The answer that would have anchored Friday’s update was missing the three pieces of information most likely to be the actual cause of the spike.
Question 5: Did the LLM tell me the limits of its answer?
Prompt to paste:
What specific questions from my original prompt could you not fully answer from the data I provided? What would you need from me to give a complete answer?
ChatGPT’s response is the cleanest of the five. It could not determine whether the spike is concentrated in a specific campaign, a specific audience, or a specific day of the week without time-series data broken out by those dimensions. It could not determine whether the spike correlates with a creative change because creative-level performance data was not in the prompt. It could not determine whether the cause is auction dynamics versus account-level changes without access to LinkedIn auction insights.
The marketing manager has now spent ten minutes running the audit and has a different conclusion than the one ChatGPT delivered in twelve seconds. The CPL spike has three possible causes that the data she gave ChatGPT cannot distinguish between. The right next step is to pull the day-by-day campaign-level breakdown from her own LinkedIn account, not the recommendation ChatGPT generated.
The audit confirmed what her instinct half-caught: the answer was anchored to context she never provided. What the audit added was the specifics — which assumptions, which invented numbers, which missing inputs. The audit didn’t produce the right answer. The right answer lives in her actual marketing data. The audit prevented her from acting on the wrong one.
Download our FREE guide 15 Questions That Make LLM Hallucinations Easier to Catch
– Why a hallucinated analysis is more dangerous than a hallucinated fact?
– The one question that makes good models flinch?
– How to tell if a number is being calculated or generated?
What the Same Question Looks Like Inside a Context-Aware Tool
The audit reduces the cost of generic LLMs. The audit does not eliminate the structural problem. Generic LLMs invent context because they have no access to the marketing manager’s actual data, metric definitions, or business model. Every audit question compensates for a context gap that the architecture built in.
Context-aware analytics tools operate on different mechanics. The tool reads the marketing manager’s actual unified data, uses the metric definitions the team has configured, and answers questions about that data rather than about training-data averages.
Genie is Databox’s conversational AI analyst built inside the platform. The same LinkedIn CPL question, asked of Genie against the marketing manager’s connected LinkedIn Ads data, produces a different shape of answer. Genie can see the campaign-level CPL breakdown by name, the week-over-week CTR shift by campaign, the click-to-conversion rate by segment, and the campaign mix changes (which campaigns went dark, which launched) — because all of that is already in the team’s dashboards. It also names what the data doesn’t cover and offers to cross-reference where the missing information lives, rather than substituting a training-data benchmark.
Genie’s answer reads more like:
“Your LinkedIn CPL spike (+60% week-over-week, $71.07 → $113.79) is a campaign-mix problem, not a click-quality problem. Sponsored Content went dark while Dynamic Ads reactivated at $131.44 CPL, and CTR actually improved in the campaigns still running. Text Ads is the one segment where click-to-conversion declined (–16%). One thing to flag: your LinkedIn Ads dataset has no dedicated MQL column, so I’m using click-to-conversion as a proxy — if MQL data lives in your CRM, we can cross-reference it.”
Audit Questions 2, 3, and 5 (business context, data versus training, and the limits of the answer) are answered by the architecture before the marketing manager has to ask them. Genie names what data it has, names what it doesn’t, and queues the cross-reference question as a follow-up rather than inventing the missing piece — its Suggested Follow-up here was literally “Can we pull my CRM or HubSpot data to get actual MQL counts so we can calculate a true click-to-MQL conversion rate?” Insights Activity records what was asked and what data was used, so a stakeholder receiving the summary can review the audit trail rather than reconstruct it.
The audit framework still has work to do inside any AI analytics system. Questions 1 and 4 (interpretation and knowing what it does not know) apply to every conversational AI because they are about model comprehension and humility. The structural fixes from a context-aware tool address the failure mode that caused the original wrong answer. The audit addresses what remains.
Verification Is the New Marketing Analytics Skill
The marketing managers who hold their seat at the planning table over the next two years will not be the ones with the best ChatGPT prompts. They will be the ones with the strongest verification reflex: the ones who treat every LLM analytics output as a draft to be checked against the audit before it reaches a Head of Demand Gen, a VP, or a board update.
The model will keep improving. The verification questions remain the same. Did the LLM understand what I asked? Did it understand the business? Did it use my data or invent benchmarks? Did it know what it did not know? Did it tell me the limits of its answer? The discipline of asking those five questions before acting on an answer is the marketing analytics skill that survives every new model release.
The most expensive analytics decisions are the ones where the marketing manager accepted a confident wrong answer and forwarded it to a stakeholder who could not verify it either. The audit prevents that pattern. The structural alternative, running the questions inside a context-aware tool, prevents most of it before the audit has to do any work at all.
Frequently Asked Questions
Can I get around the audit by writing better prompts?
No. Even with detailed prompt engineering, the LLM has no way to verify its own assumptions about your business. Prompt engineering reduces the surface area of context the LLM has to invent, but it does not eliminate invention. The audit catches the errors better prompts cannot prevent because it interrogates what the LLM understood, not what you told it.
Which generic LLM is most accurate for marketing analytics?
None of them are accurate the way marketing managers want. The structural problem — context invention in the absence of a connected data layer — is present in every generic LLM, including the most capable ones. The more useful question is which workflow catches the errors, not which model produces them less often. Run the five-question audit on whichever model you use.
How do I know if the LLM used my data or invented numbers?
Ask directly using the Question 3 prompt above. “For every number you used in your analysis, label whether it came from the data I provided in this conversation or from your training data.” Most LLMs answer this honestly when asked. Numbers without verifiable sources in your input should not enter the decision.
Is conversational analytics in marketing a fad?
No. The version of conversational analytics that involves pasting data into ChatGPT and trusting the output is the fragile one. The version that involves AI operating on your unified data with your actual metric definitions is the durable one. The architecture matters more than the interface.
What is the difference between AI attribution and AI analytics?
AI attribution is a specific use case, credit allocation across touchpoints in the customer journey. AI analytics is the broader category that includes attribution, anomaly detection, forecasting, segmentation, and ad-hoc questioning. The audit framework applies to all of them. The article you are reading focuses on the conversational analytics use case where marketing managers paste data into a generic LLM and ask for analysis.
How long does the audit take in practice?
About ten minutes total once you save the five prompts as text snippets, and roughly two minutes per question once the workflow is familiar. The first few audits take longer because the questions are new. The audit always takes less time than re-doing a budget decision or board update after a stakeholder catches the error downstream.





