




Table of contents
Your dashboards have a new reader, and it doesn’t have judgment.
TL;DR
- AI tools like Claude, ChatGPT, and Copilot now read the same dashboards your team reads, but without the organizational context that lets a human analyst flag bad numbers before they reach a decision.
- Mid-sized companies face the highest exposure because they adopted AI at an enterprise pace while keeping governance practices designed for a 12-person team: Notion docs, naming conventions, Slack threads routed to the analyst.
- Enterprise governance playbooks assume infrastructure mid-sized companies do not have: a data engineering team to maintain dbt or LookML, a dedicated CDO, a separate semantic layer outside the BI tool.
- Mid-market governance has to live inside the BI tool itself: verified metrics, named owners, semantic context AI can read, an activity log of every change. Outside the BI tool, governance drifts within weeks.
- The diagnostic takes ten minutes. If your team cannot name the official Pipeline dashboard, cannot tell you who owns the CAC definition, and cannot show AI tool a verified asset, the governance gap is already shaping AI outputs your leadership team is acting on.
Your dashboards have a new reader. It can do arithmetic faster than your analyst, spot anomalies a human would miss, and summarize three months of pipeline data in the time it takes to refill a coffee mug. What it cannot do is know that the marketing team’s MQL count has been suspect since the HubSpot reconfig in March, or that “Revenue” on the CFO’s dashboard excludes deferred, while “Revenue” on the sales VP’s dashboard includes it. Or which of the three dashboards titled “Pipeline” is the one your CRO actually opens on Tuesday mornings.
Call it the judgment gap. AI has the analytical kind. Your team has the organizational kind. The two were never supposed to meet, because the only readers of dashboards were people, and people carried the second kind in their heads. Now AI reads the same dashboards.
The output sounds confident either way.
For mid-sized companies, the practice of leaving data governance for next year’s roadmap ends now. AI tools entered the workspace faster than governance practices entered the operating model. The gap that used to produce slightly inconsistent quarterly reports now produces confident, articulate answers to executive questions, built on the wrong definition of the metric, delivered to your CRO before anyone has time to flag the error.
The new reader doesn’t have your team’s institutional memory.
An AI tool reading your dashboard is not Brandon reading your dashboard. Brandon, your analyst, sees the same numbers your AI tool sees. But, Brandon knows that the Salesforce integration broke last Friday, and the trailing-7-day pipeline figure is unusable, and that the “Enterprise” segment was redefined two quarters ago, and the prior-period comparison misleads. Brandon flags both, usually before anyone asks. AI tool flags neither.
The mechanics of how AI reads a dashboard are not the issue. AI reads the data that the workspace presents. The issue is that dashboards in most mid-sized companies have always presented data that requires human filtering: which dashboard to trust when three have similar names, which metric definition is canonical when finance and marketing have different ones, which trend line is real and which is an artifact of an integration hiccup. The judgment that filters all of this was distributed across your team’s heads, not encoded into the workspace.
AI in the workspace exposes that. Not because AI is dangerous, but because AI is fast, confident, and reads everything the same way. Three dashboards titled “Pipeline” become three equally weighted sources. The “[OFFICIAL] Q4 Revenue Forecast v3 final FINAL 2” naming convention you set up last year tells the new reader nothing about which one your team actually uses. The Notion doc that lists approved metric definitions is not in the workspace, so the new reader does not see it. Your team has been governing dashboards informally for years. The new reader does not respond to informal governance.
Every mid-sized governance workaround fails the second an AI tool reads the same workspace your team does.
Look at what governance has looked like inside a 200-person company up to now. The official Pipeline dashboard had “[OFFICIAL]” in the name. Metric definitions lived in a Notion doc whoever was on the data team last updated. When a stakeholder asked which number to trust, they posted in Slack and waited for the analyst to confirm. For ambitious teams, the answer was a semantic layer in dbt or LookML, maintained by an engineer the team had to argue to hire.
Every one of these breaks under AI.
Naming conventions break because they were never enforced. The [OFFICIAL] tag drifts within a month. Someone forks the dashboard, removes the tag, adds back two columns, and now there are two “official” versions in the workspace. AI reads both equally.
Notion docs go stale within weeks. The doc says “Revenue = closed-won, excluding deferred.” The dashboard says something different because the Salesforce integration changed in February. The doc updater forgot. The new reader reads the dashboard, not the doc.
Slack threads do not scale. The “ask the analyst” model was already a bottleneck before AI. With AI generating ten times as many analytical questions per week, the analyst becomes the single point of failure for every answer the team trusts.
Semantic layers in dbt, LookML, or Cube work when you have a data engineering team to maintain them. Mid-sized companies usually do not. The “hire a data engineer” line ignores that mid-sized SaaS budgets do not have a $180,000 engineer hidden in them, and even if they did, the semantic layer would live outside the BI tool, in a place where the Head of Revenue cannot reach when he needs to verify a number before a board meeting.
The pattern across all four: governance has lived outside the workspace where the data and the AI both live. The pattern worked when only humans read dashboards, because humans crossed the gap between workspace and governance by knowing things. AI does not know things. AI reads what the workspace tells it.
Governance for mid-sized teams has to live where the data lives.
The diagnosis points to the answer. Governance has to live in the BI tool, the same way version control has to live in the code repository. Move it anywhere else and it drifts, because the people doing the work do not visit the place where the governance lives.
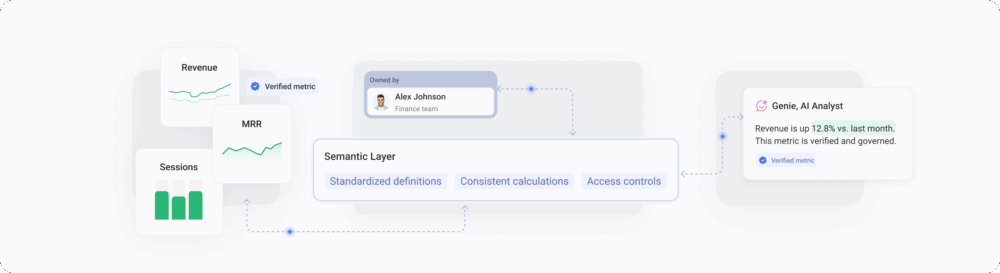
Databox built it that way. It combines ownership, roles and permissions, and the activity log into the same platform where your data lives. And with the launch of the two new capabilities: semantic layer and verification, the governance layer is complete: five components now live in the workspace, next to the metrics, dashboards, and AI that read them.
Verification puts a visible badge on any metric, dashboard, report, or dataset that has been marked as official. Anyone in the workspace can see at a glance which version of pipeline is the one your CRO actually uses. AI, reading the same workspace, prioritizes verified assets when generating answers. The badge is not a decoration. It is the trust signal both humans and AI use to know which version of a number is canonical.
Semantic layer gives AI the organizational context it lacks. Descriptions, synonyms, and default time dimensions live on datasets and columns themselves, where the data lives. When marketing calls something an “MQL” and finance calls the same thing a “qualified lead,” semantic layer lets both teams ask their AI tools (Genie and MCP) about it in their own vocabulary, and they read the canonical definition the team agreed on. The semantic layer enterprises maintain in dbt or LookML, mid-market teams can maintain inside the BI tool itself, without an engineer to keep it running.
Ownership assigns a named person to every metric, dashboard, report, and dataset accountable for accuracy and upkeep. When a number drifts, the workspace knows who to route the question to. The accountability that used to live in tribal knowledge now lives next to the asset itself.
Roles and permissions decide who can create, edit, verify, or view each asset. Sensitive financial data does not get reshaped by someone three desks away with a dashboard idea. Access scales with the company without an executive auditing every account.
The activity log records every governance action across the workspace. When a metric definition changes, the log captures who changed it, when, and what version came before. The audit trail that auditors and enterprise customers ask for now exists by default, not as a reconstruction project after the question gets asked.
Mid-sized teams do not need an enterprise semantic layer to reach good governance. They need governance that sits next to the data, owns the same surface area as the dashboards, and gets read by the same AI that reads the metrics. Databox built it that way because the alternative, asking teams to assemble a separate governance stack, is the script that has been failing for the past five years.
Five questions to test whether your dashboards are ready for the readers they already have.
You do not need a governance audit or a consultant to know whether your workspace has a judgment gap. Five questions will surface it. Ask any of them in your next staff meeting. The team’s hesitation tells you what you need to know.
1. If a board member opened your workspace and searched for “pipeline,” how many dashboards would show up, and could anyone in the room point to the one your sales VP actually uses?
If the answer is “five dashboards and we would have to check with the data team,” the official version is not marked. Verification closes the gap in an afternoon.
2. Pick the most important metric on your executive dashboard. Who owns it? Not whose team produces the underlying data. Who is personally accountable for the metric being accurate?
If the answer is “the data team” or “I think finance handles that,” ownership is unassigned. Anything unassigned drifts.
3. When marketing says “qualified lead” and finance says “qualified lead,” do they mean the same thing? Can your AI tool tell, or does it average across the conflicting definitions?
If you do not know, semantic layer is missing. The number AI reports back is a blend of two definitions neither team agrees with.
4. Pull up the activity history on your Revenue dashboard. Can you see who changed what, when, and what was edited last week?
If you cannot, change tracking is missing. Every meaningful financial number in the workspace is operating without an audit trail.
5. If an enterprise customer in their procurement review asked you to demonstrate which data your AI tools are using and how it is verified, could you show them in the workspace itself, or would you have to assemble the answer from a Notion doc, a Slack thread, and the analyst’s memory?
If it is the second one, your governance lives outside the workspace and fails the moment AI walks in.
These are the five surfaces where the judgment gap manifests in a typical mid-sized company. The teams closing the gap right now are doing it inside their BI tool, because the math of governance only works at the place the data and the AI both live.
Conclusion
AI in the workspace did not break data governance. AI revealed it had been broken for years. Humans crossed the gap between workspace and governance by knowing things, by carrying definitions in their heads, by being on Slack when the integration failed. The workaround worked because the only readers were people, and people compensated.
The new reader does not compensate. AI reads what the workspace tells it, prioritizes nothing without being told what to prioritize, and answers your CRO’s question whether or not the answer is grounded in a definition the team has agreed on. Verification, semantic layer, ownership, and the activity log are the layer that tells the new reader what your team has always known about which version of which number to trust.
Mid-sized companies are not behind on data governance. They have been told to adopt enterprise-shaped solutions for a problem that has always been BI-shaped. The fix is to put governance inside the BI tool, where the dashboards and the AI both live.
The team that adresses the judgment gap first gets AI answers grounded in their reality and the answers they can trust. The team that does not gets AI hallucinating and pulling data from the internet, presented with full confidence to leadership who does not know how to question it. Pick which team you are by Friday.
See how verification, semantic layer, ownership, roles and permissions, and the activity log work in the workspace: databox.com/data-governance
Frequently Asked Questions
What is the difference between AI data governance and the kind of data governance my IT team has always done?
Traditional data governance focuses on data at rest: storage, access, retention, backup integrity. AI data governance covers data in motion through the dashboards, metrics, and definitions that AI tools read when they answer questions in your workspace. The practical difference is that AI does not visit a Notion doc to find the canonical definition of “revenue.” AI reads whichever metric the workspace surfaces first. Governance has to live in the workspace, not next to it.
Why do “[OFFICIAL]” naming conventions break down once AI reads the same workspace your team does?
Naming conventions rely on human readers recognizing the convention and respecting it. AI reads the underlying data, not the social contract embedded in a filename. A dashboard tagged “[OFFICIAL]” reads identically to one tagged “Q4 Forecast v3 FINAL” from an AI’s perspective. Both contain numbers. AI weights them equally unless the workspace itself marks one as verified at the metadata level.
Can a mid-sized company do data governance without hiring a data engineer?
The enterprise governance playbook assumes a data engineering team to maintain a semantic layer in dbt, LookML, or Cube. Mid-sized companies usually do not have one and cannot justify the headcount. The alternative is governance that lives inside the BI tool itself, where verified metrics, semantic layer, and ownership are managed by the same people who build the dashboards. A data engineer is not a prerequisite when the governance surface is the workspace.
How can I tell if my dashboards are AI-ready?
Open your workspace and ask five questions: Can anyone point to the official Pipeline dashboard? Who personally owns the CAC definition? Can your AI tool tell the difference between marketing’s “qualified lead” and finance’s “qualified lead”? Can you see the change history on your Revenue dashboard? Could you demonstrate which data your AI is reading to a customer in a procurement review? Hesitation on any of them indicates the gap is already shaping AI outputs your team is acting on.
What does Databox’s launch of data governance actually include?
Verification and the semantic layer are the new components. Verification adds badges marking official metrics, dashboards, reports, and datasets — visible to humans and prioritized by your AI tools when generating answers. Semantic layer adds descriptions, synonyms, and time dimensions that give AI the context it needs to interpret your data correctly. Together, they complete a governance layer that already included ownership, roles and permissions, and the activity log — named accountability, controlled access, and a record of every governance change. Lineage, which traces data origin and downstream dependencies, ships in a follow-on release.image






